Elasticsearch replica shards
Resources utilized:
https://stackoverflow.com/questions/15694724/shards-and-replicas-in-elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/current/elasticsearch-intro.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/diagnose-unassigned-shards.html
https://opster.com/guides/elasticsearch/operations/elasticsearch-cat-shards/
https://bigdataboutique.com/blog/fixing-elasticsearch-unassigned-shards-644152
https://discuss.elastic.co/t/why-is-replica-shard-in-unassigned-state-if-it-exists-on-disk/118001/2
https://docs.securityonion.net/en/2.4/release-notes.html#known-issues
https://www.elastic.co/guide/en/cloud/current/ec-api-deployment-crud.html#ec_update_a_deployment
https://www.elastic.co/guide/en/elasticsearch/reference/8.13/modules-node.html
https://www.elastic.co/guide/en/elasticsearch/reference/8.13/migrate-index-allocation-filters.html
Error photo in Grid section of security onion console:

Location of log file - /opt/so/log/elasticsearch/
Log output in text:
[2024-03-29T11:44:19.913+00:00][WARN ][plugins.licensing] License information could not be obtained from Elasticsearch due to ConnectionError: connect ECONNREFUSED 192.168.80.50:9200 error
[2024-03-29T11:44:47.384+00:00][WARN ][plugins.licensing] License information could not be obtained from Elasticsearch due to ConnectionError: connect ECONNREFUSED 192.168.80.50:9200 error
[2024-03-29T11:44:49.912+00:00][WARN ][plugins.licensing] License information could not be obtained from Elasticsearch due to ConnectionError: connect ECONNREFUSED 192.168.80.50:9200 error
[2024-03-29T11:45:07.398+00:00][ERROR][plugins.security.authentication] License is not available, authentication is not possible.
[2024-03-31T23:59:57,631][WARN ][rest.suppressed ] path: /.ds-logs-*/_eql/search, params: {ignore_unavailable=true, index=.ds-logs-*}
org.elasticsearch.action.search.SearchPhaseExecutionException: Partial shards failure
at org.elasticsearch.action.search.AbstractSearchAsyncAction.onPhaseFailure(AbstractSearchAsyncAction.java:729) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.action.search.AbstractSearchAsyncAction.executeNextPhase(AbstractSearchAsyncAction.java:433) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.action.search.AbstractSearchAsyncAction.onPhaseDone(AbstractSearchAsyncAction.java:761) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.action.search.AbstractSearchAsyncAction.onShardFailure(AbstractSearchAsyncAction.java:513) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.action.search.AbstractSearchAsyncAction$1.onFailure(AbstractSearchAsyncAction.java:350) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.action.ActionListenerImplementations.safeAcceptException(ActionListenerImplementations.java:62) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.action.ActionListenerImplementations.safeOnFailure(ActionListenerImplementations.java:73) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.action.DelegatingActionListener.onFailure(DelegatingActionListener.java:27) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.action.ActionListenerResponseHandler.handleException(ActionListenerResponseHandler.java:54) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.action.search.SearchTransportService$ConnectionCountingHandler.handleException(SearchTransportService.java:630) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.transport.TransportService$UnregisterChildTransportResponseHandler.handleException(TransportService.java:1707) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.transport.TransportService$ContextRestoreResponseHandler.handleException(TransportService.java:1424) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.transport.TransportService$DirectResponseChannel.processException(TransportService.java:1560) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.transport.TransportService$DirectResponseChannel.sendResponse(TransportService.java:1535) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.transport.TaskTransportChannel.sendResponse(TaskTransportChannel.java:51) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.action.support.ChannelActionListener.onFailure(ChannelActionListener.java:37) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.action.ActionRunnable.onFailure(ActionRunnable.java:124) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:28) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.common.util.concurrent.TimedRunnable.doRun(TimedRunnable.java:33) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingAbstractRunnable.doRun(ThreadContext.java:983) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:26) ~[elasticsearch-8.10.4.jar:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642) ~[?:?]
at java.lang.Thread.run(Thread.java:1583) ~[?:?]
Caused by: org.elasticsearch.search.query.QueryPhaseExecutionException: Time exceeded
at org.elasticsearch.search.query.QueryPhase.addCollectorsAndSearch(QueryPhase.java:214) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.search.query.QueryPhase.executeQuery(QueryPhase.java:134) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.search.query.QueryPhase.execute(QueryPhase.java:63) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.search.SearchService.loadOrExecuteQueryPhase(SearchService.java:516) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.search.SearchService.executeQueryPhase(SearchService.java:668) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.search.SearchService.lambda$executeQueryPhase$2(SearchService.java:541) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.action.ActionRunnable$2.accept(ActionRunnable.java:51) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.action.ActionRunnable$2.accept(ActionRunnable.java:48) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.action.ActionRunnable$3.doRun(ActionRunnable.java:73) ~[elasticsearch-8.10.4.jar:?]
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:26) ~[elasticsearch-8.10.4.jar:?]
Log output via screenshot with error of shards

Elasticsearch error in the Kibana dashboard located in Security onion:
Go to your security onion console > Kibana > the 3 horizontal lines on the top left corner > Search > Elasticsearch

Select Indices

Notice the following Index health status’s as Yellow for shards unassigned and not allocating:
Can’t see all of your Indexes? Select the tab on the top stating Show hidden indices



Instead of diving straight into it, lets start from the beginning of understanding what ElasticSearch is completely.
What is ElasticSearch:
Elasticsearch is where distributed search analytics occur. Data that is aggregated from Logstash and beats are collected and stored within Elasticsearch where the information can be displayed into a Kibana dashboard in a pie chart, graphs or however you wish to configure your data sets for visualization. Elasticsearch however is where the indexing, search queries and analysis happens.
Bringing all Elastic, Logstash and Kibana together; we have the ELK stack.
Elasticsearch shows all types of data from unstructured text, numerical data, geospatial data, store and index data that supports fast searches.
There are a wide range of uses for Elasticsearch to be used such as:
- Search box in an app or website
- Store an analyze logs, metrics, and security event data.
- Use machine learning to automatically model the behavior of your data in real time. This machine learning technology is a Unsupervised Machine Learning model which integrates with vector databases and embeddings
Source - https://www.elastic.co/elasticsearch/machine-learning
- Can automate business workflows using Elasticsearch as a storage engine
- Manage, integrate and analyze spatial information using Elasticsearch as a geographic information System (GIS)
- Store and process genetic data using Elasticsearch as a bioinformatics research tool
Geographic information system output from Elasticsearch example with the Kibana dashboard using the Access map logs
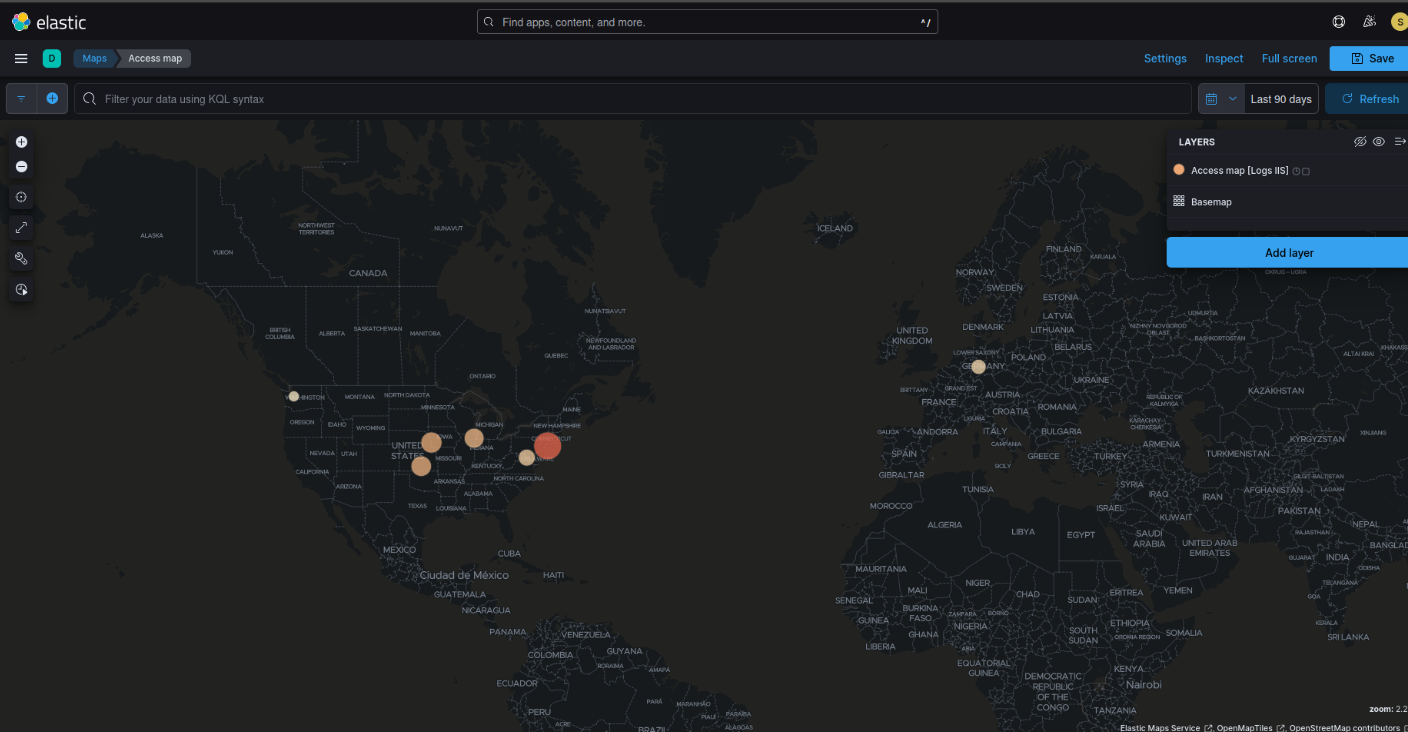
Analysis
The index analysis module acts as a configurable registry of analyzers to convert a string field into individual terms such as:
- Added to the inverted index in order to make the document searchable
- Used by high level queries such as the match query to generate terms
Source of match query - https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query.html
Index-level shard allocation filtering
Shard allocation filters are used to control where Elasticsearch allocates shards of a particular index. This is used in a per-index filters and are applied in conjunction with cluster-wide allocation filtering where Elasticsearch controls and allocates shards from any index and also uses allocation awareness which is an awareness attribute to enable Elasticsearch to take your physical hardware configuration into account when allocating shards
Shard allocation filters can be custome on node attributes or the built-in attributes such as _name, _host_ip, _publish_ip, _ip, _host, _id, _tier and _tier_preference
Delaying allocation when a node leaves
When a node leaves the cluster for whatever reason, intentional or otherwise, the master reacts by doing the following:
- Promoting a replica shard to primary to replace any primaries that were on the node.
- Allocating replica shards to replace the missing replicas (assuming there are enough nodes)
- Rebalancing shards evenly across the remaining nodes
These actions are intended to protect the cluster against data loss to ensure every shard is fully replicated as soon as possible
The example error above I initially have shows there is a shard failure as an example for the allocation of the cluster and didn’t resolve itself as it was intended.
Sample error:
[2024-03-31T23:59:57,631][WARN ][rest.suppressed] path: /.ds-logs-*/_eql/search, params: {ignore_unavailable=true, index=.ds-logs-*} org.elasticsearch.action.search.SearchPhaseExecutionException: Partial shards failure
A sample scenario described by the Elastic team:
- Node 5 loses network connectivity.
- The master promotes a replica shard to primary for each primary that was on Node 5.
- The master allocates new replicas to other nodes in the cluster
- Each new replica makes an entire copy of the primary shard across the network.
- More shards are moved to different nodes to re-balance the cluster.
- Node 5 returns after a few minutes.
- The master re-balances the cluster by allocating shards to node 5
If the missing shards waited a few minutes longer it could’ve been resolved minimaly with network traffic or could have been quicker if it was idle shards when indexing requests are not being received when flushing where it ensures data is currently only stored in a transaction log in a Lucene index.
Flush API - https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-flush.html
Transaction logs - https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-translog.html
Here is how you can query for the health of the cluster
Command – sudo so-elasticsearch-query _cluster/health
This shows the following output
Full query:
{"cluster_name":"securityonion","status":"yellow","timed_out":false,"number_of_nodes":1,"number_of_data_nodes":1,"active_primary_shards":155,"active_shards":155,"relocating_shards":0,"initializing_shards":0,"unassigned_shards":3,"delayed_unassigned_shards":0,"number_of_pending_tasks":0,"number_of_in_flight_fetch":0,"task_max_waiting_in_queue_millis":0,"active_shards_percent_as_number":98.10126582278481}

What does this output mean?
{"cluster_name":"securityonion",
This is the cluster name of my node which is securityonion. NOT the hostname of aaa004
"status":"yellow",
This is the status of the cluster node of yellow which means the replica shards on the elasticsearch cluster aren’t allocated to a node which is a problem.
The status’ for a Cluster health are described as followed:
Red – The shard is not allocated on the cluster
Yellow – Primary shard is allocated but the replicas are not.
Green – All shards are allocated
"timed_out":false,"
The node health is currently timed out when it’s being checked in every 30 seconds.
number_of_nodes":1,
This shows the number of nodes in the cluster which is 1.
"number_of_data_nodes":1,
This is the number of nodes that are dedicated data nodes which is 1.
"active_primary_shards":155,
This shows the number of active primary shards which is 155
"active_shards":155,
This shows the total number of active primary replica shards at 155
"relocating_shards":0,
This shows the number of shards that are currently being relocated which is 0
"initializing_shards":0,
This shows the number of shards that are attempting to be initialized which is 0
"unassigned_shards":3,
This shows the number of unassigned shards which are not allocated at 3
"delayed_unassigned_shards":0,
This shows the number of shards whose allocation is delayed due to timeout settings which is 0
"number_of_pending_tasks":0,
This shows the number of cluster-level changes that have not been executed which is 0
"number_of_in_flight_fetch":0,
This shows the number of unfinished fetches which is 0
"task_max_waiting_in_queue_millis":0,
This shows time expressed in milliseconds since the earliest initiated task that is waiting to be performed which is 0
"active_shards_percent_as_number”:98
This shows the ratio of active shards in the cluster expressed as a percentage
As noticed above, I have unassigned shards which is not a good thing for Elasticsearch
"unassigned_shards":3,
This shows the number of unassigned shards which are not allocated at 3 which is because since I only have one node in my network, it should not have any replica shards allocating
We are going to ssh into the management node of security onion
Command – ssh sdick@192.168.80.50

After signing in, we are going to query for unassigned shards from the API within security onion
Command – sudo so-elasticsearch-query _cat/shards?v=true&h=index,shard,prirep,state,node,unassigned.reason&s=state
Output query from all elasticsearch shards from this Node


Per the documentation within Security onion, we can query for unassigned shards from elasticsearch indices with the following command to shorten the list above.
Source of the query - https://docs.securityonion.net/en/2.4/release-notes.html#known-issues
Command - sudo so-elasticsearch-query _cat/shards | grep UN

Output given:
Index Shard Prirep State
String 1 - .ds-.logs-endpoint.diagnostic.collection-default-2024.03.23-000010 0 r UNASSIGNED
String 2 - .items-default-000001 0 r UNASSIGNED
String 3 - .ds-metrics-elastic_agent.filebeat_input-default-2024.04.07-000001 0 r UNASSIGNED
String 4 - .ds-metrics-elastic_agent.osquerybeat-default-2024.04.07-000001 0 r UNASSIGNED
String 5 - .lists-default-000001 0 r UNASSIGNED
String 6 - .ds-metrics-elastic_agent.filebeat-default-2024.04.07-000001 0 r UNASSIGNED
String 7 - .ds-metrics-elastic_agent.elastic_agent-default-2024.04.07-000001 0 r UNASSIGNED
Separated:
String 1:
Index - .ds-.logs-endpoint.diagnostic.collection-default-2024.03.23-000010
Shard – 0
Prirep – r
State – UNASSIGNED
String 2:
Index - .items-default-000001
Shard – 0
Prirep – r
State – UNASSIGNED
String 3:
Index - .ds-metrics-elastic_agent.filebeat_input-default-2024.04.07-000001
Shard – 0
Prirep – r
State – UNASSIGNED
String 4:
Index - .ds-metrics-elastic_agent.osquerybeat-default-2024.04.07-000001
Shard – 0
Prirep – r
State - UNASSIGNED
String 5:
Index - .lists-default-000001
Shard – 0
Prirep – r
State – UNASSIGNED
String 6:
Index - .ds-metrics-elastic_agent.filebeat-default-2024.04.07-000001
Shard – 0
Prirep – r
State – UNASSIGNED
String 7:
Index - .ds-metrics-elastic_agent.elastic_agent-default-2024.04.07-000001
Shard – 0
Prirep – r
State - UNASSIGNED
As you notice, the letter r is the shard type which is a replica
With the above information, I asked some friends about the Primary and replicas issue I was having with shards and some how Replicas are enabled when it can’t be enabled with only 1 node in my environment.
So we now will disable replicas in Elasticsearch
Source answer from someone I asked:
“The problem is, you can't turn on replicas when you only have 1 node
If you create an index with anything other than 1 replica, it will never go green”
He also sourced the specific documentation here - https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules.html#dynamic-index-settings
Configuring the number of replicas when using 1 Node
Syntax - sudo so-elasticsearch-query $index/_settings -d '{"number_of_replicas":0}' -XPUT
What does this syntax mean?
Sudo – Run a command as an administrative user
so-elasticsearch-query – Query within the elasticsearch docker container
$index/_settings – Controls the specific indexes settings of the elasticsearch node
-d - Data node
'{"number_of_replicas":0}' – Changes the number of replicas configured for the index of the resource
-XPUT – Pushes the query and changes the resource configuration in Elasticsearch
Bulk Strings:
String 1 - .ds-.logs-endpoint.diagnostic.collection-default-2024.03.23-000010 0 r UNASSIGNED
String 2 - .items-default-000001 0 r UNASSIGNED
String 3 - .ds-metrics-elastic_agent.filebeat_input-default-2024.04.07-000001 0 r UNASSIGNED
String 4 - .ds-metrics-elastic_agent.osquerybeat-default-2024.04.07-000001 0 r UNASSIGNED
String 5 - .lists-default-000001 0 r UNASSIGNED
String 6 - .ds-metrics-elastic_agent.filebeat-default-2024.04.07-000001 0 r UNASSIGNED
String 7 - .ds-metrics-elastic_agent.elastic_agent-default-2024.04.07-000001 0 r UNASSIGNED
Now we will configure the replicas from
String 1 - .ds-.logs-endpoint.diagnostic.collection-default-2024.03.23-000010
Command - sudo so-elasticsearch-query .ds-.logs-endpoint.diagnostic.collection-default-2024.03.23-000010/_settings -d '{"number_of_replicas":0}' -XPUT

String 2 - .items-default-000001
Command - sudo so-elasticsearch-query .items-default-000001/_settings -d '{"number_of_replicas":0}' -XPUT

String 3 - .ds-metrics-elastic_agent.filebeat_input-default-2024.04.07-000001
Command - sudo so-elasticsearch-query .ds-metrics-elastic_agent.filebeat_input-default-2024.04.07-000001/_settings -d '{"number_of_replicas":0}' -XPUT

String 4 - .ds-metrics-elastic_agent.osquerybeat-default-2024.04.07-000001
Command - sudo so-elasticsearch-query .ds-metrics-elastic_agent.osquerybeat-default-2024.04.07-000001/_settings -d '{"number_of_replicas":0}' -XPUT

String 5 - .lists-default-000001
Command - sudo so-elasticsearch-query .lists-default-000001/_settings -d '{"number_of_replicas":0}' -XPUT

String 6 - .ds-metrics-elastic_agent.filebeat-default-2024.04.07-000001
Command - sudo so-elasticsearch-query .ds-metrics-elastic_agent.filebeat-default-2024.04.07-000001/_settings -d '{"number_of_replicas":0}' -XPUT

String 7 - .ds-metrics-elastic_agent.elastic_agent-default-2024.04.07-000001
Command - sudo so-elasticsearch-query .ds-metrics-elastic_agent.elastic_agent-default-2024.04.07-000001/_settings -d '{"number_of_replicas":0}' -XPUT

Next we will query the elasticsearch cluster for the cluster health
Command – sudo so-elasticsearch-query _cluster/health
and as we can see, all shards are healthy 100 percent after pushing cluster configuration changes to the stack
Green status means it’s a healthy cluster

We will now restart the elasticsearch container with the following command
Command – sudo so-elasticsearch-restart

After restarting the elasticsearch container, wait around 30 minutes (depending on your resources) for all primary shards to allocate properly then check the cluster health and ensure it’s in a Green state meaning all shards are allocating correctly to the management node
We will also confirm the Security onion console is in a running state as well


Sigma Playbooks
Initial installation of Security onion - Sigma Playbooks
Source post with resolution - https://github.com/Security-Onion-Solutions/securityonion/discussions/11707
When installing Security onion initially, all nodes will be in running status and good condition. Which is correct, but the issue is sigma playbooks preconfigured didn’t properly download to the Security onion management node in my case with a fresh install
Note – I Fixed it prior to making this documentation, but pretend the image below is blank and has no output of information for any sigma playbook rules. This does not matter even if you are logged into playbooks as nobody or an admin, it will not display information. See photo below as rules are downloaded from a non-logged in user account. This interface should be accessible regardless unless the container is offline.

To verify the Playbooks container is running, please input the following command below on your Security onion Manager:
Command - sudo so-status
Expected output:

If you however are noticing an error from the playbooks container running, check and verify the logs as presented below. Or if it’s still not running, the directory path as we read on here should be presented still in theory for the salt master output.
Location of log output - /opt/so/log/playbook/
Source - https://docs.securityonion.net/en/2.4/playbook.html#diagnostic-logging
Small screenshot for reference of a known good output:

After going through the logs not being presented, I then thought about how the data is sent and downloaded. I then went to the security onion github discussions and someone stated about the API links missing along with the integration for all the operating systems Sigma Playbooks by default downloads
Source of github - https://github.com/Security-Onion-Solutions/securityonion/discussions/11707
Deleting the value of the Automation API Key located in the salt master for playbooks /opt/so/saltstack/local/pillar/secrets.sls then reloading playbooks did however obtain an API Key, but was not downloading any playbooks still.
Expected screenshot prior to reloading the saltmaster for sigma playbooks:

After running so-playbooks-reset I was still not seeing any playbooks downloaded as stated before.
I then moved toward the saltmaster configuration where the initial configuraiton of the type of playbooks should be being pulled from the API
Location of the configuration for the saltmaster of sigma playbooks - /opt/so/saltstack/local/pillar/soctopus
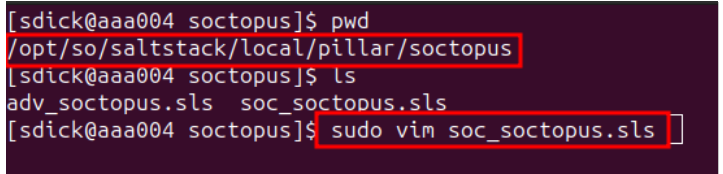
After opening the saltmaster of the configuration input the following within the configuration file. Yours will be blank for the rulesets most likely
Location in Security onion Docs - https://docs.securityonion.net/en/2.4/playbook.html#adding-additional-rulesets
Input the following:
soctopus:
enabled: true
playbook:
rulesets:
- windows,application,category,cloud,compliance,linux,macos,network,web
Expected configuration:

Press Esc key and type :wq to save it
Run the command below to restart the Playbooks container and apply the changes from the salt master to the salt minion
sudo so-playbook-restart

Expected output should be showing the changes are properly applied:

Open your Security onion Console and Select Playbooks

Sigma Playbooks will begin to slowly start downloading and presenting itself within the Playbooks web user interface even if you aren’t signed in.
Photo below of all Sigma Playbooks rules (5498 roughly at the time of this article):
